info@biomedres.us
+1 (502) 904-2126
One Westbrook Corporate Center, Suite 300, Westchester, IL 60154, USA
Site Map
Received: May 23, 2024; Published: May 31, 2024
*Corresponding author: Nikolaos Loukeris, University of West Attica Department, Business Administration, Petrou Ralli & Thivon, 111 00 Athens, Greece
DOI: 10.26717/BJSTR.2024.56.008910
Further advancing the Optimal Returns Integration Network – ORION, Loukeris [1], the diagnosis of bubbles
and their potential returns is produced innovatively to elaborate significant parameters of the welfare
optimization, such as:
I. Trends on patients’ patterns,
II. TheEntropic effect on patients in the Chaotic effects of the Virus infections in SDEs by Tsallis Statistics and
the FHR - Fractal Health Reaction,
III. To propose an optimal classifier on 60 Modular Networks of Neurals or Hybrid Neuro-Genetics to support
the optimal health policy. The SElectively Integrated Returns Intelligent Optimisation System – SEIRIOS is
introduced as an intelligent health optimization system in Medicine.
Keywords: Health Optimization; Modular Networks; Genetic Algorithms; Kappa Distributions; Chaotic Dynamics; Tsallis Statistics; Entropy, Medicine; Surgery; Diagnosis, Immune System; Inflammation; Disease
During the Second Phase of the therapy portfolio selection are required advanced higher moments [2] (ultrakurtosis, hyperultrakurtosis, etc), [3-7], depicting advanced forms of risk. Initially a feasible set of therapeutically combination policies is produced by the evaluated therapy portfolio, resulting to the efficient frontier where the utility function [8-11], is maximized on return under minimal risk, [12-15] expressed as an almost adequate approach of a maximum Sharpe ratio. The paper examines the first step that resolves the second step. I examine 60 Modular networks - MDN- of neural or hybrid neural-genetic combinations: 20 Modular Neural Networks and 40 Hybrid MDNs, of altered topologies to define the optimum classifier for portfolio selection. The paper:
i. Analyses the therapy selection that patients have under further
higher moments, in certain returns and risk levels,
ii. Supports further the Isoelastic Utility as a sufficient norm,
iii. Evolves the Therapeutical Portfolio Theory, [16], extracting covered
patterns on health fundamentals indices, excluding bias, detecting
robust stocks, under Chaotic Entropy of FHR
iv. Investigates the performance of the Modular Networks in hybrid
or neural or models, revealing the optimum classification model
that fits intense therapy.
v. Utilises the SEIRIOS model on therapeutical portfolio optimisation.
The Entropy of Chaos, [17] in the form of Relative Entropy-TRE produces the Kullback-Leibler Relative Entropy – KLRE - for systems unextensive, on nonlinear, complex systems of long memory. [18-24] evaluated in practice the markets on a KLRE, Tsallis approach.
The complicated behavior of patients requires further moments [6,7,12,13,25]:
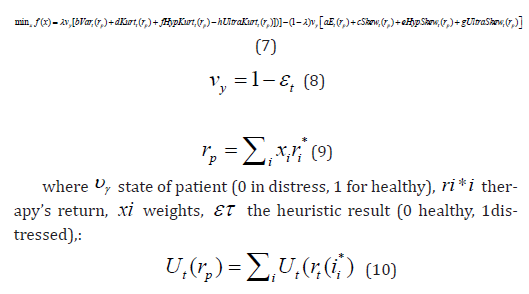
Robust computing abilities are necessary to the heuristics for the solution process of the non-convex problem. I provide an advanced classifier that detects hidden corporate info, especially hoaxes to support the decision-making process of investors.
The Recurrent and Modular neural and hybrid neuro-genetic networks are comparatively analysed in a variety of classifiers forms.
The Self Organized Features Maps-SOFM neural net, [26], is optimized for clustering, and data examination. The unsupervised learning trains SOFM producing a 2 Dimensional map. The discretized input surface of training set reduces dimensionality. The SOFM implements competitive learning, whilst the inputs givens as 16 financial indices have an unknown significance in the SOFM nets. In the hybrid forms, Genetic Algorithms-GA [27], were incorporated on the:
i. Inputs layer only,
ii. Inputs and outputs layers only,
iii. All layers,
iv. All layers with cross validation.
The training of each model is extensive to converge to a model of the lowest error. GAs is implemented in different hybrids and the Batch learning method was applied to the SOFM to adjust the weights (Figures 1 & 2).
Figure 1

Figure 2

The Recurrent Neural Nets -RNN- create a directed cyclical grid in connections of feedback. The RNN have different elaboration than the feedforward systems. RNNs can have chaotic performances. Their ordinal problems are resolved by the Long Short- Term Memory -LSTMapproach [8], in cases of:
i) Temporally extended noisy patterns recognition,
ii) Temporal order in noisy widely separated events recognition,
iii) Temporal distance between events, data extraction,
iv) Smooth & anomalous periodic trajectories, stable generation of
precisely timed rhythms,
v) Extended time intervals, robust storage of high-precision real
numbers. Genetic Algorithms optimized the RNNs [1,7], on 4 alternative
topologies.
The Genetic Algorithms were selected to optimize RNN models, in terms of selecting the inputs, and the performance of neurons. The learning method of On-Line is selected to adjust the Recurrent Hybrids weights, and thus optimize the:
a) Amount of Neurons,
b) Size of Step, and
c) Rate of Momentum, as the output optimised the Momentum and
size of Step in the Gas (Figures 3 & 4).
Figure 3

Figure 4

The feedforward Modular - MDN – nets, consist a variation of the Multilayer Perceptrons. The MDNs process inputs in parallel numerous MLPs and recombines the outcomes. The network topology thus forms a structure specialised in the function of each sub-module. From the four MDN topologies, the linear feedforward topology with no bypasses is put in all the models. The MDNs contradicting the MLPs, are lesser interconnected. Thus fewer neurons weights are required for the same size model. Training is boosted with fewer examplars. The optimal operation to provide the MDN topology is fuzzy, feeded by the data, and no reassurance that a module emphasizes the training on a specific part of the data. This paper elaborates 16 Inputs neurons, 1 Output, 706 Exemplars, 4 Upper Neurons without GA into Hidden layers, on the Upper Transfer TanhAxon, Lower Transfer function on the TanhAxon, 4 Lower Neurons, Learning Rule of Momentum, 0.1 Step size, 0.70 Momentums. The learning technique is the Backpropagation, the previous value and a correction term adjusts the weights. Every correction is adjusted by the learning rule. Batch learning technique, 1000 Maximum epochs was the value of the Supervised Learning Control regarding the number of iterations, over the training set to be done by default, the Termination choice is under Minimum MSE below the specified Threshold, in 0.01 threshold, technique of Load best on test. The default Incremental error is significantly less than the Minimum error. The termination on MSE sets the stop criteria on the Cross Validation than the training set. If the MSE of the Cross Validation increases, the model commences overtraining, memorizes the set of training, unable of generalizing the problem (Table 1). Cross validation is used twice in the models on 20 different sets, as an efficient termination of training (Figures 5 & 6).
Table 1: Optimal outcomes of modular, SOFM and recurrent networks overall [14].

Figure 5

Figure 6

Inspired by my models the ORION [12,13,28] the new integrated Selectively Integrated Returns Intelligent Optimisation System – SEIRIOS, initially reads the fundamentals, prices and time, selecting the first classifier of therapy assets, patientss risk profiles, and λ
Advanced higher moments demonstrated their impact on the model [1,6,7,29], to support a logical reflection of investment patterns and their dynamic behavior. [1,12,13] contributed:
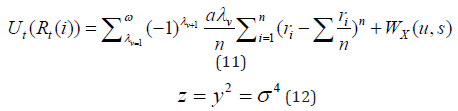
through [1], to manipulation in superior risk. A risky asset works in the Dynamics of Chaos and Stochastic Differential Equation [26]:
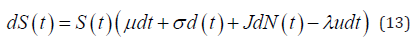
where μ the expected asset return, σ the volatility without jumps, J the jump amplitude on asset > −1, random variable.
u = E (J ),{N (t ),t ≥ 0}Poisson process of strength λ , λ udt an average growth by Poisson jump, {W (t ), t ≥ 0} the Brownian motion of probability ({Ft} t ≥ 0, P), {N (t ) , t ≥ 0}and {W (t ), t ≥ 0}independent, [26]. The non-convex problem needs higher computational resources to undergo the heuristics. Inflammatory reaction, false diagnosis, inefficient therapy, hoaxes, require reliable valuation of the firm. The SDE’s (14), solution is [27,30]:
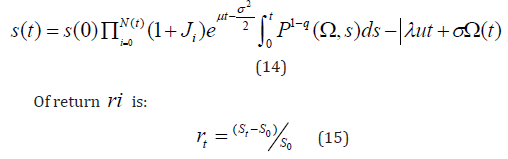
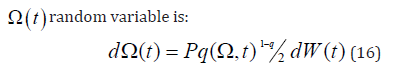
where Pq(Ω,t ) is the maximum Distribution Entropy by Tsallis in Non-extensive statistics. (17) describes the clustering of volatility and long-term memory effect in assets [26]. (11) describes the optimal utility [29,30]. The Kappa distributions can extend its support in the bubbles management (of diagnosis, therapy, inflammation) (Figure 7).
Figure 7

The data came can be results of medical tests and their desired outcome. In the past the model was tested inv16 financial indexes data of 1411 cases, [30], as the17th index has the classification of executives. The test set was 50% overall, and training 50%. Numerous combinations required to find the optimal MDN and RNN Nets:
i. MDN neural networks
ii. MDN neural nets with Cross Validation
iii. MDN neuro-genetic hybrids with GA on the Inputs only
iv. MDN neuro-genetic hybrids with GA on the Inputs and Ouputs
only
v. MDN neuro-genetic hybrids with GA in All Layers
vi. MDN neuro-genetic hybrids with GA in All Layers with Cross Validation
vii. RNN neural networks
viii. RNN neural nets with Cross Validation
ix. RNN neuro-genetic hybrids with GA on the Inputs only
x. RNN neuro-genetic hybrids with GA on the Inputs and Ouputs
only
xi. RNN neuro-genetic hybrids with GA in All Layers
xii. RNN neuro-genetic hybrids with GA in All Layers with Cross Validation
xiii. SOFM neural networks
xiv. SOFM neural nets with Cross Validation
xv. SOFM neuro-genetic hybrids with GA on the Inputs only
xvi. SOFM neuro-genetic hybrids with GA on the Inputs and Ouputs
only
xvii. SOFM neuro-genetic hybrids with GA in All Layers
xviii. SOFM neuro-genetic hybrids with GA in All Layers with
Cross Validation
The Modulars group, [13] MDN Neural Net in 3 layers classified optimally the assets in healthy and distressed: 99.16% and 83.48% respectively, of high fitness of the model to the data in 0.884, the lowest MSE at 0.092, NMSE 0.218 and 4.611%, the AIC was very low at -1230.98 revealing impartiality in a very fast time of 26s as in Table 1. In the Recurrent Networks on the other hand, the optimal performance of the RN Hybrids was in the model of 1 layer with GAs in the inputs only, in high classification rate of the healthy companies at 98.99%, and 96.6% for the distressed, the lowest MSE at 0.038, and 0.0935 in NMSE, the highest fitness of the model into the data 0.986, the AIC had the lowest value at -2062.4 indicating an ideal fitness of the model, similarly for the MDL at -2062.4, at a fast time of 54 minutes and 40seconds, in an over- optimisation hazard. Regarding the SOFMs, the Neural Network of 7 layers had the best results, in mediocre classification, high errors, low fitness, and significant partiality, (Table 1) [31,32].
The Hybrid Recurrent networks of 1hidden layers and Genetics on the input layer only, had superior classification and performance in a fast processing time, the Recurrent Neural Net, ranked second overall in a good performance and a very fast time. The Modular and SOFM networks underperformed significantly and shouldn’t be considered as a classifier potential to an health portfolio optimiser system such as the SEIRIOS.

























