info@biomedres.us
+1 (502) 904-2126
One Westbrook Corporate Center, Suite 300, Westchester, IL 60154, USA
Site Map
Received: January 20, 2023; Published: February 01, 2023
*Corresponding author: Usman Khalil, School of Digital Science, Universiti Brunei Darussalam, Jalan Tungku Link, Gadong BE1410, Brunei Darussalam
DOI: 10.26717/BJSTR.2023.48.007641
National Health and Nutritional Status Survey (NHANSS) is conducted annually by the Ministry of Health in Negara Brunei Darussalam to assess the population’s health and nutritional patterns and characteristics. The main aim of this study was to discover meaningful patterns (groups) from the obese sample of NHANSS data by applying the data reduction and interpretation techniques. The mixed nature of the variables (qualitative and quantitative) in the data set added novelty to the study. Accordingly, the Categorical Principal Component (CATPCA) technique was chosen to interpret the meaningful results. The relationships between obesity and lifestyle factors like demography, Socio- Economic status, physical activity, dietary behavior, history of blood pressure, diabetes, etc., were determined based on the principal components generated by CATPCA. The results were validated with the help of the split method technique to counter-verify the authenticity of the generated groups. Based on the analysis and results, two subgroups were found in the data set, and the salient features of these subgroups have been reported. These results can be proposed for the betterment of the health care industry.
Keywords: NHANSS; Data Mining; Machine Learning; Categorical Principal Component Analysis; CATPCA; NCD; Obesity
Obesity is one of the non-communicable diseases that is a condition of being overweight or a major nutritional disorder that has become a worldwide epidemic. Its growth has been projected at 40% in the upcoming decade [1]. It is often defined simply as a condition of abnormal or excessive fat accumulation in adipose tissue to the extent that health may be impaired [2]. Not only is being obese problematic but with that comes the risk and complications of other non-communicable diseases (NCDs) that can be life-threatening if not taken care of at the right time, e.g., hypertension/high blood pressure, diabetes, etc. [3]. Diseases can be communicable and noncommunicable diseases; the names refer to the type as the diseases spread (by different means) from one individual to another, such as pneumonia, malaria, hepatitis-A and C, HIV/AIDS, measles, etc. At the same time, the latter is not transmissible directly from one person to another. Obesity, cancer, heart disease, diabetes mellitus, cerebrovascular disease, hypertension, high blood pressure, high cholesterol levels, etc., are all NCDs [1,2].
WHO Obesity Classification
WHO defined obesity as an accumulation of excessive body fats in tissues to the extent that health may be impaired. BMI measures it in kg/m2 [2,4,5]. It further defined the Overweight and obesity for adults as follows; BMI more than equal to 25 kg/m2 for Overweight; and BMI more than equal to 30 kg/m2 for Obese [2,6-8]. Obesity has been further classified as BMI more than equal to 30kg/m2. It includes an additional sub-division as BMI more than equal to 30kg/ m2 and less than equal to 34.9 kg/m2 for obese class-I, BMI more than equal to 35kg/m2 and less than equal to 39.9 kg/m2 for obese class-II and BMI more than equal 40 kg/m2 for obese class-III [2-4,9- 11]. However, this classification does not completely consider the population-level heterogeneity and cannot identify the variations among obese individuals. There is evidence of the association of obesity with other factors, including demographics, nutritional habits, and individuals’ physical activity [7,8]. In our case, Body Mass Index (BMI) was calculated and inserted into the dataset as a variable feature to study the characteristics of obese people and the prevalence of obesity [1,6]. This survey also used the same variable features like demographic status, diet patterns, and physical activity together with the history of raised blood pressure, diabetes, and raised cholesterol with BMI measurements as done in the studies carried out in the past [8].
ASEAN Strategic Framework on NCDs
Taking a step ahead, the Brunei Darussalam government has taken significant measures to handle the NCD-related issues in its population [3]. Following the World Health Organization (WHO) Global Action Plan to control the prevalence of non- communicable diseases (NCDs) and the ASEAN Strategic Framework on Health Development [10]. The government has well anticipated the execution of the plan and has initiated a Multisectoral Action Plan on NCD (BruMap-NCD) 2013-2018 to control NCDs and related risk factors. It includes a ban on all kinds of smoking products in the country with a 30% reduction in smoking prevalence and a 10% reduction in physical inactivity prevalence by 2018 from the 2013 level [3]. According to this National Action Plan on the Prevention and Control of Noncommunicable Diseases (BruMAP-NCD) 2013-2018, Brunei’s 1st National Nutritional Status Survey (NNSS) was carried out in the year 1997. Around 32% of the population was overweight, and 12% were obese among 20 years old and above [2,6]. This obese percentage, in particular, was increased by more than double to 27.2% in the year 2011 [3,11,12]. The current statistics show that around 61% of Bruneians are overweight and obese, the highest rate in ASEAN [2,5,6,12].
Obesity Prevalence in Brunei Darussalam
Brunei Darussalam is an oil & gas producing country and is one of the member countries in the ASEAN (Association of Southeast Asian Nations) organization. It is situated in Southeast Asia on the northern coast of Borneo Island, neighboring its borders directly with Malaysia. Its population is estimated at 417,200, with gross domestic products (GDP) per capita of USD 28,986 [6]. There has been a noticeable rise in non-communicable diseases (NCDs) as aforementioned [1], while obesity, one of NCDs, has been of major concern for its occurrence. The government has been targeting management and prevention from the grassroots level to overcome this problem, including childhood obesity. It requires long-term strategies and treating childhood obesity may likely help manage obese adults in the future [2,5]. The study’s focus has been on the prevalence of obesity and the lifestyle factors affecting it. Past studies have shown that it has been one of the major risk factors causing other non-communicable diseases such as diabetes and cardiovascular problems [7-9]. The threat of obesity related NCDs, especially chronic kidney diseases (CKD), is preventable by educating the population about the risks of being obese and prevention through a healthy lifestyle [5]. In 2014, over 600 million adults aged 18 years and above were obese worldwide [5].
National Health and Nutritional Status Survey Data
The data was provided by the ministry of health Brunei Darussalam which runs parallel with the Brunei Darussalam Household Expenditure Survey (HES) 2010/2011 implemented by the Department of Economic Planning and Development, Prime Minister’s Office [11]. NHANSS, the acronym for National Health and Nutritional Status Survey, is conducted annually to access the population’s health and nutritional patterns and characteristics [11]. The data includes all the lifestyle aspects regarding demographics, Socio-Economic status, physical activity, and laboratory examinations. The Ministry of Health (MOH) designed the data collection process and carried it out in three phases. Sampling procedure, questionnaire development, database development, and testing. Like others, NHANSS is also a cross-sectional survey aimed at the population aged from 5-to 75 years old, with an initial target of 2184 participants from all the districts in Brunei Darussalam. All the health offices under the ministry of health were included for data collection, including Tertiary Care Hospitals, Health Offices in Districts, Health Clinics, and the Community Nutrition Centre were used as survey sites. Face-to-face interviews with parents and/or caregivers (for children) and participants themselves were conducted by trained dietitians/nutritionists and research assistants using a questionnaire booklet [11]. The measurements, including anthropometric indices such as weight, height, and waist circumference, were taken. Blood pressure readings were also noted for all respondents using standard methodology [13], while individuals aged 20 years and above were additionally asked for biochemical measurements. Before the final data collection, a test run was carried out on the survey procedures and questionnaire to have standardized data collection [3,11,13,14].
Categorical Principal Component
The field of study interested in developing computer algorithms to transform data into intelligent action is known as machine learning [15]. Machine learning techniques have been used to explore the details mentioned above, which have been of great importance to extract the useful knowledge from the data that normally is received from a group of individuals through a survey or a questionnaire, or other health-related data collection techniques [15,16]. Categorical Principal Component Analysis (CATPCA) is one of the techniques applied to the data sets with more variables to reduce the dimensionality of the data set by ensuring as much variation as possible and, most importantly, applied to the set of qualitative and quantitative variables. The goal of the technique is to reduce an original data set into a smaller set of uncorrelated components (variables) that represent most of the information found in it. It removes a large number of correlated variables that may affect the interpretation of the patterns projected by the reduced variables. By dimensionality reduction, a few components with high variance interpret the patterns rather than many components with no or low variance. The choice of the technique was evident and applied to the NHANSS data set as discussed in Section 1.4 to generate meaningful patterns as far as obesity prevalence in the community was concerned. The review of the obtained results may help the health care industry to classify the characteristics of patients for a particular disease and to use that information to improve the protocols and procedures for the better treatment of patients by the clinicians and, most importantly, for the betterment of humanity in general [8,16,17].
Research Objectives
Focusing on the same idea, the objectives in this research were set as follows
• We explored the NHANSS data set and identified subgroups within the obese sample by implementing the machine learning technique.
• We resolve the pre-processing data issues by applying missing values analysis, imputation analysis, and data normalization techniques.
• We review and analyze the generated patterns by dimensionality reduction for obesity and the factors affecting it.
• We interpret and profile the salient characteristics of subgroups based on result validation.
• Finally, we provide insightful reviews and discussions on generating potential recommendations and relevant information about the affecting factors of obesity to clinicians for preventive measures.
Paper Organization
The rest of the paper is organized as follows. Section 2 elaborates on the overall NHANSS obese sample, data processing issues, interpretation, analysis, and results from validation classification methods. Section 3 presents the CATPCA analysis and the validation process and finalizes the profiling to generate salient characteristics of the obese sample. Finally, a concise conclusion is presented in Section 0 at the end.
The overview of the model methodology to carry out the study has been provided in Figure 1. Data was taken from the NHANSS – 2017 provided by the Ministry of Health, Negara Brunei Darussalam, representing data collection and selecting the variables in the first step. The second step follows the data pre-processing for any missing values or normalization issues so that data can be applied with the machine learning techniques. The categorical principal component analysis (CATPCA) extracted the components by reducing the dimensions and classifying the data. In this research, the classification technique was tested, and the process of validation was carried out to check the authenticity of the generated results. At the same time, the last step concludes the interpretation by profiling the observed classes. The results, validation, and profiling steps were carried out to understand and present the intelligible data for reporting. Since the motive was to find the meaningful patterns, Figure 1 shows the steps performed for identifying the subgroups of the obese in a given sample. The steps below mentioned were followed,
1) NHANSS ~ Obese Sample
2) Data Pre-Processing
3) Classification Method
4) Interpretation & Analysis (Results & Discussion)
5) Results Validation.
NHANSS ~ Obese Sample
As discussed in Section 1.4 and to study the characteristics of the obese population within the obese classes (I-II-III), the NHANSS data set (National Health and Nutritional Status Survey) was filtered with the number of people having BMI ≥ 30 kg/m2. Out of the total sample of 2184 records, 449 were filtered with 20.55% percent, and the required set of variables was chosen. A subset data set was chosen from the NHANSS data, whereas all the variables were included based on evidence-based research on obesity [7,13,18]. Since the obese sample had mixed variable types, the data type measurement for the variables was defined as quantitative and qualitative. It also added to the study’s novelty as not many studies on the obesity affecting factors have been carried out in the past with mixed variables data types. The level of measurement for quantitative variables was numeric, while for qualitative variables, the level of measurement was set either nominal (for not ordered data) or ordinal (for ordered data). In Step 3 in Figure 1, the machine learning technique was applied once the data was pre-processed. The CATPCA (categorical principal component analysis) was chosen for this study because of its ability to handle qualitative and quantitative data.
Figure 1.

Data Pre-Processing
Like the other surveys, the NHANSS is a cross- sectional survey conducted among all age groups in all four districts. Figure 2 lists the details for data collection [7,10,13]. As represented, 67.70% of the data was collected from Brunei Muara, the most densely populated, 17% from Kuala Belait, 12% from Tutong, and 3.30% from Temburong, being the lowest among all. A comprehensive questionnaire was prepared to note down the critical information, which was taken in several groups, such as;
Figure 2.

1) Demographics
2) Socio-Economic status
3) Medical / Smoking Status
4) Physical Activity Patterns
5) Anthropometric Measurements
6) Multiple Dietary Patterns
7) Bio-Chemical measurements on Adults and Children.
The NHANSS data set with 2184 instances and 88 variables were pre-processed for missing values after missing value analysis. Since the data set was already inputted with the missing values, the data set was further analyzed. This sample was representative of obese individuals from all three classes of obesity. It had 449 instances with 88 variables (86 excluding BMI and Obesity factor as evaluating factors) for the CATPCA analysis. The level of measurement for all the variables was ordinal, while there were 14 numeric (Scale) variables whose normalization was taken care of by SPSS with a normal distribution. The data points were processed in SPSS Ver. 20 and since the obese NHANSS data set was used with 86 variables and 449 instances, the representation of number of variables (m) were X1, X2, X3…….X86 i.e., m = 86 (e.g. X1= age years, X2 = Urban, X3 = DistCd and so on to…………. X86 = Salt93) while (n) represents the number of instances i.e., n=449 for obese sample. Demographic variables were selected, such as age, sex, marital status, etc., [19] for physical activity, the recreational activities such as vigorous or moderate activities were selected. For sedentary characteristics, the time spent watching TV and resting/reclining variables were taken as per their importance in the earlier studies [7,20]. Age was reported as a continuous variable (quantitative), while sex, ethnicity, etc., were reported as categorical variables (qualitative) [16]. Time spent for vigorous/moderate activities, watching TV, and resting/reclining time were taken as continuous variables since they indicate the importance of sedentary characteristics with time spent on it [19]. Dietary intake was self-reported through a questionnaire provided to the subjects in NHANSS data collection [11]. It was reported in categorical variables format in levels from 1 to maximum 7, varying for different variables with numbers 666 for not known and 999 for not applicable, respectively [19].
Results Validation
For validation purposes, the split method was used. The obese data set was divided into two data sets more cases from class I (187), with a percentage of 59.56%, is the highest among the classes, followed by class II (85) with a percentage of 27.07% being second highest and then class III (42) with a percentage of 13.37% being the lowest respectively.
Categorical Principal Component Analysis
Categorical principal component analysis (CATPCA) is applied to the data sets with more variables of mixed data types, i.e., qualitative and quantitative variables [21]. It reduces the dimensions of the data set by increasing variation as much as possible [18]. It is also referred to as Nonlinear Principal Component Analysis (PCA) [19], which works opposite of how PCA works. Nonlinear PCA reduces the observed variables to several uncorrelated variables [21]. If the measurement level of the variables is scaled to numeric, then PCA will be an alternative to CATPCA. Therefore, it would not be wrong to say that CATPCA is an alternate analysis technique to PCA when the analysis required is to find the patterns of variations in a single data set of mixed data types [22]. When PCA handles mixed quantitative and qualitative data, the qualitative data must be quantified and is known as nonlinear PCA [18]. The CATPCA solution maximizes correlations of the object scores with each of the quantified variables for the number of components (dimensions) specified. The CATPCA application is only available in IBM® SPSS®. If applied to all variables that are declared multiple nominals, CATPCA produces an analysis equivalent to a named train data set and test data set by a ratio of 70:30, which means 449 instances were divided by a ratio of 314:135, respectively. First, the results were generated by applying CATPCA on train data set with 314 instances. These results were compared to validate principal components by applying the same technique to the test data set (135 instances) later on. The descriptive statistics of obesity factors are presented in Table 1 with classes I, II, and III mentioned against obesity factors 1, 2, and 3 (1st column), respectively. The obesity factor was the representation of obesity classes in the data set. It can be seen that there were multiple correspondence analysis (MCA) run on the same variables, so CATPCA can be seen as a type of an MCA in which some of the variables are declared ordinal or nominal [22].
Table 1: Obese Sample ~ Train Data Set.

Note: a. Mode
Component Extraction Methods: As discussed in the section above, one of the most important purposes of PCA / CATPCA methods is dimension reduction. In order to achieve the purpose, some criterion has to be applied, whose method may follow the same principles to reduce the dimensions. Selecting only a few Principal Components (PCs) that share less of the variance may not help as this might result in selecting too few PCs and reducing the dimensions a lot. Similarly, selecting all the PCs will also be of no use just because they explain most of the variance of the data and may not help as this might result in selecting most or all the PCs and not reducing the dimensions at all. It may not fulfill the essence of the dimension reduction method.
Component Extraction Criterions: The principal components that share the maximum variance should be the benchmark to select and reduce the dimensions. However, other defined criteria can be applied by looking at the data’s nature. The different criteria available can be applied according to the nature of the data in the view. Four types of criteria can be used and are discussed below mentioned.
Eigen Value Criterion:
1) The proportion of Variance Explained Criterion
2) Minimum Communality Criterion
3) Scree Plot Criterion
Eigen Value Criterion: As per the eigenvalue criterion, a principal component must explain “one variable’s worth,” which would mean that the PCs must have an eigenvalue of 1 at least. Eigenvalue Criterion may be best suited for data sets with more than 20 and less than 50 variables if the data set has less than 20 variables. The criterion may choose too few principal components, and if the data set has more than 50 variables, then the criterion may choose too many principal components. In either case, it may not be feasible to analyze and later outline the characteristics of those c h o s e n dimensions/components [18]. For instance, if there are the principal components PC1, PC2, and PC3 have eigenvalues 𝜆1 = 1, 𝜆2 = 0.85, 𝜆3 = 0.075 respectively then according to this criteria PC1 may be the only component retained, and the rest may be discarded. PC2 can also be retained as the eigenvalue is close to the threshold eigenvalue of 1, so in this case, two principal components may be retained, i.e., PC1 and PC2.
The Proportion of Variance Explained Criterion: This criterion mostly depends on the analyst who specifies the total number of principal components considering the variability. The PCs must be selected until the desired proportion of the variability explained is attained. The total proportion of the variability can be explained by Equation (2.1) below,
Where,
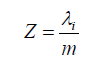
The equation represents the proportion of variability in Z, which is explained by the ratio of ith eigenvalue for the ith principal component to the number of variables. For instance, if a data set has ten variables applied with CATPCA results with eigenvalues against respective principal components and the first principal component has an eigenvalue of 𝜆1 = 4.901; then, as per equation 2.1, since there are ten variables (m), the first component may explain 4.901/10 = 49.01% of the shared variance among the predictor variables. Suppose the required percent of shared variance among the predictor variables is 85%. In that case, more principal components may be added so that the desired number of components should attain the desired percent explained by the variability.
Minimum Communality Criterion: PCA / CATPCA does not present all the variance from the variables but only a proportion of the variance shared by the predictor variables. Communality plays an important role in extracting the proportion of a particular variable. Communality shows how beneficial the variable is for contributing to the CATPCA in terms of sharing the percent of the variance. If the variable shares less percent of the variance, it contributes less and vice versa, showing how beneficial the variables are to CATPCA. Suppose it is required to keep a certain set of variables in the analysis. In that case, most of the components with their weights are to be extracted so that the communality for each variable exceeds the minimum threshold of communality significance, i.e., 50%. It can be calculated as the sum of squared component weights for a given variable [15].
Scree Plot Criterion: The scree plot criterion has been used to extract the maximum number of components to work with. A Scree plot is a graphical representation of the eigenvalues against the component number and is very helpful in finding several components for further analysis. It always starts with a high value along the y-axis as it represents the eigenvalue for the first principal component explaining much of the shared variance. Later on, the line starts to dip along the x-axis as the eigenvalues for the rest of the principal components share a lesser and lesser percentage of the variance. The significant knee of the line in two dimensions shows the number of principal components to be selected [22].
CATPCA was applied to the obese sample, which started with 0 iterations. The accounted variance of 87.045800 for all the variables at 0 iterations was achieved. Table 2 further shows the iteration history of the CATPCA process. As depicted, the iterations stopped with an accounted variance of 87.108862 for all the variables at 100 iterations.
Table 2: Iteration History ~ Train Data Set for Obese Sample.

Note: a. Iteration 0 displays the statistics of the solution with all variables, except variables with optimal scaling level Multiple Nominal, treated as
numerical.
b. The iteration process stopped because the maximum number of iterations was reached.
Table 3: Model Summary ~ Train Data Set for Obese Sample.

Note: a. Total Cronbach’s Alpha is based on total Eigenvalue.
Principal Component Selection Criteria
As depicted in Table 2, the CATPCA algorithm finished iteration, and the eigenvalues were generated for all the 86 principal components with accounted variance shared by each of them. As noted in Table 3, the dimensions that share the maximum percent of the variance were selected. The first dimension shown in the table had an eigenvalue of 8.372, and it shares 9.74% of the total variance, which happens to be the highest percentage of shared variance among all the PCs, the eigenvalue was not very high, and that’s because of the greater number of dimensions. Following the first dimension, the second- dimension shares 3.756% of the total variance similarly fifth until tenth and eleventh until thirty- first shares almost the same percentage of the total variance, i.e., ≥ 2 and ≥ 1 respectively. Since the percentage was getting lower than 1%, choosing dimensions was obvious, i.e., 31 dimensions. The next seven eigenvalues for the principal components were not very far from the threshold value of 1, so these components were also included. These dimensions shared 80.23% ≈ and 80% percent of the total variance, which was not as good as required, but this was the maximum number of dimensions best suited for this data set. The relevant criterion to extract the principal components was checked and finalized in the next section.
Component Extraction Criterion
As discussed in Sections 2.4.1 to 2.4.2.4, the criterion was to be applied to the results to finalize the PCs so that profiling can be processed to know the characteristics of these PCs, respectively. The results presented by the algorithm in Table 3 give us the model summary for the percent of variance shared by all the PCs. Based on these eigenvalues, it was further evaluated to suggest and extract the number of dimensions and PCs. Further presented in the table are the 86 dimensions for 100% of the shared variance in the data set. These dimensions were evaluated with criteria, and then the profiling of these PCs was finalized. The Eigenvalue criterion selected thirty-eight dimensions sharing an approximate 80.23% ≈ 80% of the total variance, which supports the theory of its tendency to extract more dimensions of variables in the dataset are > 50 variables. The proportion of variance explained criterion selected 44 dimensions sharing an approximate 85.56% ≈ 86% of the total variance. The knee of the scree plot depicted in Figure 3 suggested two principal components sharing an approximate 14.10% ≈ and 14% of the total variance to work with. Since all the criteria were analyzed and applied to extract the exact number of components, finally, it was agreed to apply the eigenvalue criterion to extract the number of principal components. It was due to consideration of the said criterion for the variables that had eigenvalue ≥ 1 as it defines the one’s variable worth; it also extracted a lesser number of principal components (38) comparatively with a reasonable percent of shared variance among the PCs, i.e., ≈ 80%. A total of 38 principal components reduced from 86 principal components were considered, as shown in Table 3. Before profiling the principal components, the component weights also had to be evaluated.
Figure 3.

Once the dimensions were chosen for the shared percent of variance by the principal components, it was time to evaluate and extract the components based on their factor weights. For evaluation of the component weights, the weight threshold value equal to +/- 0.50 was considered to retain the component, which would define its contribution to CATPCA as a whole. The components that had component weight less than +/-0.50 were to be excluded as the decided threshold value in this research was +/-0.50 or values close to it. Finally, 28 principal components were further excluded based on criterion and component weights, with ten principal components retained for profiling. The principal components extracted were PC6, 10-12, 14-26, and 28-38. An overview of the extracted PCs concerning the factors within respective PCs has been presented in Figure 4. The figure shows all factors within PC along the y-axis, while along the x-axis are extracted PCs. As discussed in Section 3.1, it is noticeable that PC1 has most of the variables count (PC1 = 16 variables), which correlates with the percent of variance shared among the PCs as normally, the first PC has the maximum percent of the shared the factors allotted to respective PCs. Later on, all the principal components are discussed to note the salient features of all the PCs, respectively.
Principal Component 1: PC1 presented in Table 4 is composed largely of the “block group size” variables, namely, history of raised blood pressure: tablets taken (53a), diet (53b), lose weight (53c), stop smoking (53d), start exercise (53e), history of diabetes: blood sugar measured in past 12 months (56), tablets taken (60b), diet (60c), weight loss (60d), smoking (60e), start exercise (60f), history of raised blood cholesterol: tablets taken (65a), diet (65b), weight loss (65c), stop smoking (65d), and start exercise (65e) all have large values referred to as high levels. The values presented in Table 4 show that these variables were right skewed. It means most individuals were not receiving any advice from the doctor or treatment in terms of tablets, prescribed diet plan, weight loss, stop smoking habit, start or stop the exercise as far as the history of raised blood pressure was concerned. The same trend was observed for a history of diabetes and a history of high blood cholesterol. PC1 shares the maximum percentage of variance by factors. The salient characteristics showed that this component belonged to healthy individuals with no history of raised blood pressure, diabetes, and high blood cholesterol.
Figure 3.

Table 4: Components Extraction ~ CATPCA.

Principal Component 2: Table 4 depicts PC2, which is about demographic status, Socio-Economic status, smoking status, recreational activity, and body image. It showed that most of the individuals were female (6). Mostly never smoked any tobacco products such as cigarettes, cigars, or pipes in recent times (24). The body image showed that the individuals in this principal component had heavyweights (73) and heights (74) along with their waists (75).
Principal Component 3: PC3 presents the demographic characteristics of the sample as presented in Table 4. The age in years and values were noted high and increasing concerning obesity which means this variable had contributed well to CATPCA. Most of the individuals were elderly aged (1).
Principal Component 4: PC4 presents the sample’s demographic, socio- economic, smoking, and health characteristics in Table 4. The level states that most individuals lived in the main districts (DistCd) of Brunei Darussalam. They were Brunei Citizens (8) and did not smoke daily (33) tobacco products such as cigarettes, cigars, or pipes.
Principal Component 5: PC5 in Table 4 presents physical activity status, history of raised blood pressure, and blood cholesterol. It showed high values for all the factors. The individuals in this PC did not know about being told by a doctor or health worker about having high bp or hypertension (52); similarly, they had never been told by a doctor or health worker of high blood sugar levels or diabetes (57) during the past 12 months. They also had never been told by a doctor or health worker about high blood cholesterol (64) during the past 12 months.
Principal Component 7, 8, 9: PC7, 8, and 9 in Table 4 present the individuals’ demographic status, body image, and short food frequency status. PC7 depicts that most individuals were Muslim belonging to the religion (10) Islam. PC8 & PC9 in Table 4 presented the body image and short food frequency status of the obese sample. Most of the individuals considered themselves Overweight (69) and were not satisfied with their body weights (70), while most of the people were used to eating nasi katok (90) and Chicken Tail / Wings / Skin (91) twice a week.
Table 5: Components Loadings ~ Train Data Set for Obese Sample.

Principal Component 13: PC13 in Table 4 depicts Socio- Economic status with high values. It depicts that most individuals had electricity and water piped supply (13 and 14) to their houses.
Principal Component 27: PC27 in Table 4 represents the health status which showed that most of the individuals were suffering from anemia (68f) as far as health was concerned.
Minimum Communalities Criterion
As discussed in Section 2.4.2.3 and Table 3, the variable that shares less communality means shares less of its common variability among the variables, and contribution to the CATPCA is also considered lesser. At first, the finalized PCs were compiled concerning the factor variable weights (≥ +/-0.50), as highlighted in Table 5. The communality values showed the contributing factor variables. 35-factor variables out of the total 86 variables met the criteria, and the rest were omitted. In the second step, all the respective PCs’ weights (Table 5) according to the communality criterion were calculated with their squared weights. Table 6 depicts the squared weights for all the factor variables in respective PCs. It shows the squared component loadings for the 25-factor variables that met the criteria by having a communality significance value ≥ 50% showing their contribution to CATPCA. It means these are the final set of factor variables that have contributed well to the algorithm as a whole. CATPCA classified the NHANSS data into two subgroups; one subgroup was presented with left-skewed distribution while the other was presented with rightskewed distribution, which means that the most prevalent conditions concerning obesity by variables were either detected or undetected. The variables that presented the communality significance more than the threshold (50%) value were the variables that helped gain knowledge about the salient characteristics of the NHANSS obese sample. As discussed above, the generic details of these variables are below mentioned for reference.
1) Demographic and Socio-Economic Characteristics
2) Smoking Characteristics
3) History of Raised Blood Pressure
4) History of Diabetes Mellitus
5) History of High Blood Cholesterol and,
6) Anthropometric Characteristics
Table 6: Squared Components Loadings Communality ~ Train Data Set for Obese Sample.

Table 7: Model Summary for Test Data Set ~ Obese Sample.

Validation of Principal Components ~ Obese Sample
As discussed in Section 2.3, the test data set taken from 449 instances (obese sample) was divided with a ratio (70:30) of 314:135, respectively. CATPCA generated the results on the test data set, and then these results were compared for validation of principal components with those already generated aforementioned. It was noticeable that the results generated by the train data set did not show much difference concerning the selection and extraction of components for further evaluation. The process started with 0 iterations and ended at 100 iterations. As shown in Table 7, the shared variance was noted 87.999 as a whole by the CATPCA. The model summary was generated against the eigenvalues representing the percent of variance shared among the principal components. To evaluate these PCs and to know whether this test data set had also generated the same number of PCs, a comparison had to be made to indicate whether these results for the data set as a whole are generalized or not, so the results can be reported as Valid or Invalid. The eigenvalues starting from PC1, both the data sets, train, and test data sets, almost shared the same percentage of variance reported as 8.372 and 9.954, respectively. Similarly, for PC2, the eigenvalues were reported as 3.756 and 4.421, respectively. For PC3, the eigenvalues were reported as 3.261 and 4.057, respectively, and so on. Here, it is wise to compare the criterion results from train and test data sets to see if the reported results were the same as those of eigenvalues or if they differ significantly. If there were a minimal difference in the number of selected PCs or shared variance, it would validate the results, but if vice versa, then the validation would be reported as invalid as far as the reporting of the results was concerned. Since the eigenvalue criteria were finalized for the train data set, the results concerning the eigenvalue criterion generated by the test data set were checked and compared for validation.
Eigen Value Criterion ~ Test Data Set: The results in Table 7 showed the same trend of extracting more PCs in terms of dimensions as the data set had more than 50 variables. Hence, the criterion suggests extracting exactly 31 dimensions with eigenvalue ≥ 1. The next three proceeding dimensions with eigenvalues close to 1, i.e., ≤ 0.85, were added. A total of 34 dimensions were suggested by this criterion, sharing approximately 82.79% ≈ 83% of the total variance, which again supported the theory of its tendency to extract more dimensions (if variables in the data set are > 50 variables). Comparing it to the eigenvalue criterion results generated by the test data set seems to validate the results generated by the train data set, as discussed in Section 3.3. The eigenvalue criterion on the test data set suggested 34 dimensions with an estimated shared percent variance of 83%, which validates the eigenvalue criterion results generated by the train data set (the suggested result was 38 dimensions with an estimated shared percent variance of 80%). The results did not show any huge difference in the dimensions’ shared percent variance, and almost the same number of dimensions were selected. It shows that these details validate the results generated by the train data set and now can be reported as Valid.
Obesity is one of the non-communicable diseases that is a condition of being overweight or a major nutritional disorder. The prevalence of obesity in Brunei Darussalam has increased more than double since 1997, to 27.2% in 2011, and around 61% of Bruneians are overweight and obese, which is highest in the ASEAN region. Comparatively, in the US, the prevalence of obesity in 2011-2014 was 22.8% (including obese and extremely obese individuals) among the youth aged 2-19 years which shows that obesity has become a worldwide epidemic. Its growth has been projected at 40% in the upcoming decade. In this study, the classification technique was used to identify the obesity subgroups within the NHANSS data provided by the ministry of health, Brunei Darussalam. The novelty of the research was to extract useful knowledge from NHANSS data of mixed variable types as not many studies have been carried out in the past in this domain with mixed data types. CATPCA algorithm was used, which grouped the obese sample into two classes concerning the anchoring conditions related to obesity. The two subgroups presented the most prevalent conditions belonging to demographic, Socio-Economic, smoking, anthropometric, and short food frequency characteristics of the obese sample. The short food frequency revealed that the obese group was not taking care of their diet and was used to eating nasi katok (local rice cooked with fried chicken) and chicken Tail / Wings / Skin twice a week. Noticeably the history of blood pressure, diabetes mellitus, and high blood cholesterol were undetected for obese patients, but most of them were reported as having anemia as far as their health was concerned. All of these results were validated, and profiling was noted accordingly. This research is of clinical importance, and the salient features should be reported and further investigated from a medical perspective. The proposed approach reveals the sub-groups that may help investigate the importance of the lifestyle factors (i.e., age, smoking habits, blood pressure, diabetes mellitus, high blood cholesterol, etc.) from a clinical point of view. Overall, the combination of clinical knowledge with data-hidden information and the evaluation of subclasses revealed by the data structure could lead to very interesting developments.
The authors would like to express sincere appreciation for the technical assistance and support from the Department of Economic Planning and Development Brunei Darussalam, research assistant, and managers from the Ministry of Health Brunei Darussalam, and participation from the survey respondents.
The author(s) declared no potential conflicts of interest concerning this article’s research, authorship, and/or publication.

























