info@biomedres.us
+1 (502) 904-2126
One Westbrook Corporate Center, Suite 300, Westchester, IL 60154, USA
Site Map
Received: August 01, 2022; Published: August 11, 2022
*Corresponding author: Davide Frumento, PhD, University of Genova, Genova (GE), Italy
DOI: 10.26717/BJSTR.2022.45.007233
Acute myocardial infarction (AMI) represents a critical problem across all European Union, both in terms of incidence and economic burden. Such phenomenon is mainly due to the increasing prevalence of multiple cardiovascular risk factors. Since Italian demographic course have dramatically changed as a consequence of senior citizens number growth during last few decades, this country may be considered as an emblematic case-study among European member nations. Cardiovascular risk factors were identified to be obesity, diabetes, cigarette smoking, atherosclerosis, dyslipidaemia and sedentary lifestyle, diffused among elderly people. Such diseases represent both the first cause of mortality and morbidity in Italy, while related drug treatments are accounted as responsible for 32% of the annual pharmaceutical costs. If there was a both fast and accurate mathematical algorithm to predict AMI incidence, lawmakers could optimize assets allocation well in advance, allowing a huge money saving to the country. Since western society is living a very economically difficult era, and although such an amount has yet to be calculated, a tool like the one implemented in the present paper in mostly needed. Our aim was to develop a reliable and robust predictive model, suitable for AMI incidence forecasting over a year in the future, attempting to evolve our previous models and move to the creation of a general predictive method, functioning regardless to the type of entered data.
Keywords: Forecasting; Infarction; Incidence; Statistics; Epidemiology
Both incidence and costs of acute myocardial infarction (AMI) represent a critical problem across all European Union, mainly because of the increasing prevalence of multiple cardiovascular risk factors. Since Italian demographic trends have visibly varied as a result of elderly subjects number growth during last decades, Italy may be considered as a very interesting case-study among European countries. Data released by the Italian Institute for Statistics (ISTAT) show a life expectancy increasing of 4 months per year, from 1950 to 2002 [1]. Higher life expectancy is coexisting with both increased fragility of senior citizens and cardiovascular diseases augmented prevalence [2-9]. Cardiovascular risk factors are, among others, diabetes, obesity, cigarette smoking, dyslipidaemia, atherosclerosis and sedentary lifestyle, diffused among elderly people [10-14]. Cardiovascular diseases represent both the first cause of mortality and morbidity in Italy [1], while related drugs are held responsible for 32% of the national pharmaceutical costs [15]. The current mortality rate due to AMI has been calculated to be 15% [16-18]. Our aim was to develop a reliable and robust predictive model, suitable for AMI incidence forecasting over a year in the future, attempting to evolve our previous models and move to the creation of a general predictive method, functioning regardless to the type of entered data.
The hereby described model is the evolution of the previously published E-MuSER (Enhanced Multiple Sclerosis Expected Rate) algorithm [19], realized to forecast the Multiple Sclerosis incidence on the Italian territory. Such method was implemented to extend the single-year prevision set with MuSER (Multiple Sclerosis Expected Rate) model, a rougher version previous to E-MuSER [20], to a 5-years span. Originally, MuSER employed a simple interpolation carried out on the basis of a linear regression, operated by entering incidence data on the ordinate axis and time data on the abscissa one. Reliability was raised by cancelling outliers, up to obtain R2 values higher than 0.90 and conserving a minimum of n = 5. Subsequently, E-MuSER was implemented by unpacking data series, obtaining 2 dispersion graphs and obtaining a mean incidence value, calculated between unpacked data series, using the interpolating lines equations. Such elaboration increased theoretical accuracy from 93.76% (± 2.43) to 99.35% (± 1.02) [20].
TIFoM (Triplets Interpolation Forecasting Model) was developed in order to ameliorate the previously employed method and to operate on interpolation parameters (i.e., angular coefficient and intercept) instead of rough data. Italian data about Acute Myocardial Infarction (AMI) were extracted from Italian Statistics Institute (ISTAT) website [21], filtering them by selecting male sex individuals from 0 to 95 and more years of age, from 2003 to 2019. Such choice was made because of the higher risk of AMI among men. Time upper limit corresponded to the last available year data. Such data series was graphed, by placing time parameter on abscissa axis and the incidence parameter on the ordinate one (Figure 1). Time measure unit was converted in ordinal numbers, so that the subsequent operations of data series unpacking could be carried out, rendering the derived series compatible with the original one. Incidence/Year data couple were unpacked in triplets, adopting the following scheme: 1-2-3, 2-3-4, 3-4-5, etc., where such ordinal numbers correspond to years. The last triplet had the third incidence and year missing: those were the data to forecast. By doing this, it was possible to obtain a total 15 graphs, each containing a dispersion of 3 points (Figure 2); after applying a linear regression to every graph, a total of 15 interpolating line equations were obtained [22].
Figure 1: Absolute annual Italian incidence of acute myocardial infarction among male subjects, aged from 0 to 95+ years. Time frame: 2003 – 2019.

Equations showed the following pattern:
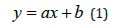
In such pattern, a represented the line’s angular coefficient, while b was the associated intercept. Both angular coefficients and intercepts were separately tabulated, each one coupled with the corresponding time variable (year), converted in ordinal numbers [23]. Then, each table was converted in a dispersion graph, in order to perform a new linear regression, eventually obtaining and interpolation line equation (Figures 3A & 3B). Its pattern was equal to (1). Next, such equations were employed by substituting to the “x” in the equation the ordinal number corresponding to year 2020; in this way, estimated values for both angular coefficient and intercept were calculated. Such values represented the a and b constants related to the missing triplet’s interpolating line equation.
Figure 2: Unpacking of incidence data into triplets. Every graph contains its interpolation equation, used to both extract angular coeffiecient and intercept. Abscissa axis: incidence; Ordinate axis: years expressed as ordinal numbers.

Figure 3:
A. Interpolation of angular coefficients extracted from the 15 graphs resulting from incidence data unpacking. Abscissa axis: angular coefficient (absolute value); Ordinate axis: years expressed as ordinal numbers.
B. Interpolation of intercepts extracted from the 15 graphs resulting from incidence data unpacking. Abscissa axis: intercept (absolute value); Ordinate axis: years expressed as ordinal numbers.

TIFoM (Triplets Interpolation Forecasting Model) was developed in order to address two issues, namely evolving E-MuSER (Enhanced Multiple Sclerosis Expected Rate) model and moving towards a general disease incidence forecasting algorithm, regardless to the disease type. Previously, E-MuSER theoretically reliability was evaluated on the basis of R2 value (99.35% ± 1.02), but its dependability will be assessed in 2023. It must be underlined that, despite E-MuSER theoretic precision was higher than the MuSER’s one (93.76% ± 2.43), MuSER accuracy was proven to be unsatisfactory. So, since E-MuSER employed the same direct interpolation method, although data were unpacked, it was decided to operate on the interpolating line parameters, by subdividing data in triplets and obtaining smaller and more controllable data sets. Such approach permitted to work on pure tendency parameters, avoiding operations on raw data. TIFoM model limitation is represented by the absence of other variables outside of time and incidence.
Calculations brought to the following equation:
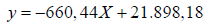
The unknown incidence value was calculated by inserting the missing ordinal number associated to time (year), so the expected Italian acute myocardial infarction (AMI) incidence among males from 0 to 95+ years of age for 2020 is 10.670,819.
Since Italian Statistics Institute (ISTAT) website still did not release such incidence value for 2020 and subsequent year (2021), precision of TIFoM model will be assessed once data will be available.

























