 Review Article
Review ArticleAbstract
In this paper, the Markov Chain Monte Carlo (MCMC) method is used to estimate the parameters of Logistic distribution, and this method is used to classify the credit risk levels of bank customers. OpenBUGS is bayesian analysis software based on MCMC method. This paper uses OpenBUGS software to give the bayesian estimation of the parameters of binomial logistic regression model and its corresponding confidence interval. The data used in this paper includes the values of 20 variables that may be related to the overdue credit of 1000 customers. First, the “Boruta” method is adopted to screen the quantitative indicators that have a significant impact on the overdue risk, and then the optimal segmentation method is used for subsection processing. Next, we filter three most useful qualitative variable According to the WOE and IV value and treated as one hot variable. Finally, 10 variables were selected, and OpenBU-GS has been used to estimate the parameters of all variables. We can draw the following conclusions from the results: customer’s credit history and existing state of the checking account have the greatest impact on a customer’s delinquent risk, the bank should pay more attention to these two aspects when evaluating the risk level of the customer during the COVID-19 pandemic.
Keywords:Data analysis; Monte Carlo model; Open BUGS; Overdue risk
Introduction
The Markov Chain Monte Carlo method (MCMC), originated
in the early 1950s, is a Monte Carlo method that is simulated by
computer under the framework of Bayesian theory. This method
introduces Markov process into Monte Carlo simulation and
achieves dynamic simulation in which the sampling distribution
changes as the simulation progresses, which makes up for the
shortcoming that traditional Monte Carlo integral can only simulate
statically. MCMC is a simple and effective computing method, which
is widely used in many fields, such as statistics, Bayes problems,
computer problems and so on. Credit business, also known as
credit assets or loan business, which is the most important asset
business of commercial Banks. By lending money, the principal and
interest are recovered, and profits are obtained after deducting
costs. Therefore, credit is the main means of profit for commercial
Banks during the COVID-19 pandemic.
By expanding the loan scale, the bank can bring more income,
and inject more power into the social economy, so that the economy
can develop faster and better. However, with the expansion of
credit scale, it is often accompanied by risks such as overdue credit.
Banks can reduce credit overdue risk from two aspects, one way
is to increase the credit overdue penalties, such as lowering the
personal credit, dragging into the blacklist, and so on. with the
rapid development of Internet, personal credit registry has more
and more influence on the individual. A bad credit report will bring
much inconvenience for the individual, so, in order to avoid the
adverse impact on your credit report, borrowers tend to repay the
loan on time, but these means are all belong to afterwards, although
reduced the frequency of overdue frequency, but still caused a
certain loss to the bank.
Selectively lending to “quality customers” can reduce
Banks’ credit costs even more if they anticipate the likelihood of
delinquency in advance, before the customer takes out the loan.
How to identify whether the client is the “good customer” will
need to collect overdue related information about the customer
in advance, algorithm, and this algorithm has the property that its
output value is always between 0 and 1. So logistic regression is a classification algorithm whose output is always between 0 and
1. First, let’s take a look at the LR of the dichotomy. The specific
method is to map the regression value of each point to between 0
and 1 by using the SIGmoid function shown in Figure 1.

Figure 1: Sigmoid function.
As shown in the figure Z = w.x + b when z > 0, the greater z is, the closer the sigmoid returns to 1 (but never more than 1). On the contrary, when z < 0, the smaller z is, the closer the sigmoid return value is to 0 (but never less than 0). This means that when you have a binary classification task (positive cases corresponding labeled 1, counterexample corresponding labels 0) and samples of each of the sample space for linear regression Z = w.x + b , then the mapping using sigmoid function of g = sigmoid (z), and finally output the corresponding class label each sample (all value between 0 and the one greater than 0.5 is marked as positive example), then, two classification is completed. The final output can actually be regarded as the probability that the sample points belong to the positive example after the model calculation [1].
Thus, we can define the general model of the dichotomous LR as follows:

For a given input x, p (Y =1/ X ) and p (Y = 0 / X ) can be obtained, and the instance x will be classified into the category with high probability value. Odds of an event refers to the ratio between the probability of its occurrence and the probability of its nonoccurrence. If the probability of its occurrence is P, the probability of the event is P/(1-P), and the log odds or logit function of the event is

That is, the logarithmic probability of output Y=1 in the logistic regression model is a linear function of input X. When learning logistic regression models, for a given data set
T = {( x1,y1),( x2,y2).....( xN,yN)
xi∈ Rn,yi∈ {0,1} The maximum likelihood estimation method can be used to estimate the model parameters, and then the logistic regression model can be obtained. set
p (Y =1/ x)π (x), p (Y = 0 / x) =1−π (x)
The likelihood function is

By gradient descent algorithm and newton method can get the maximum value in the L(w) and the estimates of w: w∧ then the logistic regression model :

MCMC
The formula of Markov Chain is as follows
p( Xt+1= x / Xt, Xt-1...)= p(Xt+1=x / Xt)
That is, the state transition probability value is only related to
the current state. Let P be the transition probability matrix, where
Pij represents the probability of the transition from i to j So we can
prove that lim

Where π is the solution to π p =π . Since the probability of x obeys π (x) after each transfer, it is possible to sample from π (x) by transferring the different bases to this probability matrix. Then, given π (x) , we can construct the transition probability matrix by the Gibbs algorithm.

Data Description and Preprocessing
The German credit card data set is adopted in this paper, which contains 20 variables, including 7 quantitative variables and 13 qualitative variables. The details are shown in Table 1. The data set includes 20 variables, the influence of different variables on credit overdue is different, adopting too many variables will not only increase the cost of collecting data, and wast customer’s, also increases the complexity of the model, reduce the accuracy of prediction, so before to fitting the model we need to screen all the indicators which have a significant effect. The following content will be introduced from the screening of quantitative indicators and the screening of qualitative indicators.

Table 1: Data specification.
“Boruta” Screening of Quantitative Indicators
The goal of Boruta is to select all feature sets related to dependent variables, which can help us understand the influencing factors of dependent variables more comprehensively, so as to conduct feature selection in a better and more efficient way.
Algorithm Process:
a) Shuffle the values of various features of feature matrix X, and combine the post-shuffle features and the original real features to form a new feature matrix.
b) Using the new feature matrix as input, training can output the feature_importance model.
c) Calculate Z_score of real feature and shadow feature.
d) Find the maximum Z_score in the shadow features and mark it as max Z.
e) The real feature whose Z_socre is greater than max Z is marked as “important”, the real feature whose Z_score is significantly less than max Z is marked as “unimportant”, and is permanently removed from the feature set.
f) Delete all shadow features.
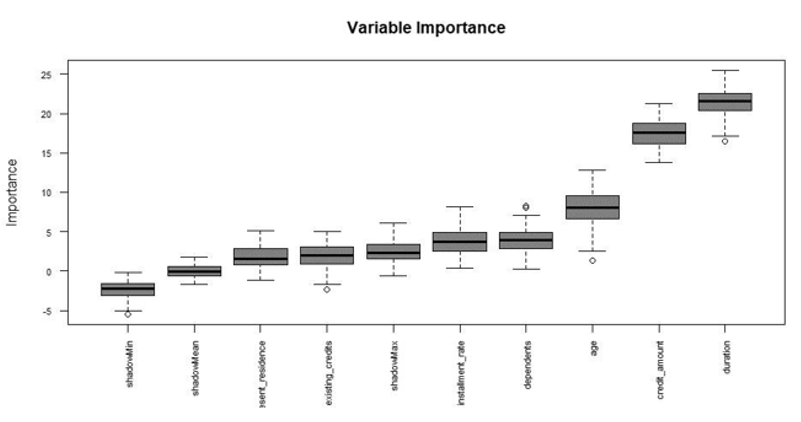
Figure 2: Quantitative variable importance.
g) Repeat 1 to 6 times until all features are marked as
“important” or “unimportant” The importance order of
quantitative variables using the Boruta package of R software
is shown in Figure 2.
The first three quantitative variables duration, creat_amount
and age were selected into the model in order of importance,
and the continuous variables were divided into boxes, with WOE
(weight of evidence) and IV (Importance Value) values dividing the
variables with the best predictive ability into groups.

Where goodi stands for the number of good tags in each group, goodT for the total number of good tags; The same for bad.

Where N is the number of grouped groups, and IV can be used to represent the grouping ability of a variable, as shown in Table 2. To make the difference between groups as large as possible, smbinning package in R softwear is used to segment the continuous variable duration, credit_amount and age using the optimal segmenting method. The result of segmenting is shown in Figure 3. The Duration loan variable was divided into three sections: [0,11], (11,33) and (33,+∞); Credit_amount loan amount (a continuous variable) was divided into four paragraphs: [0,3446] and (3446,3913], (3913,7824], (7824,+∞]; The Age of the Age applicant is divided into [0,25] and (25,+∞). All segments of the variable are corresponding to the WOE value with a large difference, indicating a large difference between groups. The IV value calculated according to the WOE value of the group are respectively duration: 0.225, Credit_amount: 0.229, age: 0.073.

Table 2: IV VS. Ability to predict.

Figure 3: Optimal segmentation of continuous variables.
Screening of Qualitative Indicators
IV values were calculated for all types of variables and sorted from high to low. Since the data only contained 1000 rows and the sample size was relatively small, only variables with large IV values, namely those with obvious classification effect, were selected in this paper. Three variables with IV values greater than 0.15 were selected, and the results were shown in Table 3. For each of the three selected qualitative indicators, the possible values of the variables are matched to a 0-1 variable. For example, the variables checking_account_status are treated as

variables A11, A12, A13, and A14,Variables may have values as shown in the Table 4.

Table 3: Screening of qualitative indicators.

Table 4: Variables values.
Step Forward Likelihood Ratio Test
After preprocessing, there are 17 variables, not all of which have significant influence on the overdue risk. Before fitting the model, variables with small correlation and more significant significance are screened out, which can not only improve the classification accuracy of the model, but also simplify the model and reduce the cost of collecting customer information for Banks [2]. Variables with significant influence on overdue risk were selected by using the forward likelihood ratio test. The simulation results of SPSS are shown in Table 5.

Table 5:Step forward likelihood ratio test result.
Model Training and Prediction
The significance level was set as 0.05. A total of 10 variables were screened to establish the model:

Where β0 is the constant term, (β1=1,2,...,10) is the partial regression coefficient of independent. Variable Parameters of the model have been given independent “non-informative” prior distribution, and OpenBUGS software is used for modeling and sampling, as well as Doodle modeling through OpenBUGS, to specify the distribution type and logical relationship of various parameters, as shown in the Figure 4: Each ovals represent a node IN the graph, rectangle with constant node, single arrow from the parent node to the random child nodes, hollow double arrows indicate the parent node to the logical type child nodes, the rectangular outside for tablet, the lower left corner “for (I IN 1: N)” said for loop, is used to calculate the likelihood function of all samples, and the overall likelihood function is obtained [3]. The posterior distribution statistics for each parameter were obtained using OpenBUGS software, as shown in Table 6.

Figure 4: Doodle model.

Table 6:Parameter estimation result of MCMC.
Where, MC_error represents the error of monte Carlo simulation
and is used to measure the variance of the mean value of parameters
caused by simulation. Val2.5 PC and VAL97.5 PC represent the
lower and upper limits of the 95% confidence interval of the
median, respectively; Median is usually more stable than mean;
Start represents the starting point of Gibbs sampling. In order to
eliminate the influence of initial value on sampling, sampling is
started after 1001 times. Sample represents the total number of
samples extracted. A total of 10,000 samples were extracted in this
paper [4]. According to the parameters of Bayesian estimation, the
error of model Colot simulation is generally relatively small, which
indicates that the model has a good effect. With each parameter of
the Gibbs sampling sample mean as a parameter to estimate, from
the point of the results, the variable whether checking_account_
status values for A13 (greater than 200 DM) and A14 (no checking account), variable credit_history whether values for
A30 (not credit) and A31 (have to pay all the bank’s credits) have
bigger influence on the overdue risk, relative variable savings for
A61 values (<100 dm) and A62 (100
When dividing the overdue risk level of customers, there may be two wrong divisions, that is, dividing “high-quality customers” into high-risk customers and high-risk customers into “high-quality customers”. Generally speaking, the economic costs of these two wrong divisions are different. For Banks, the cost matrix is shown in the Table 7 (0=Good, 1=Bad) [6]. the rows represent the actual classification and the columns the predicted classification. It is worse to class a customer as good when they are bad (cost=5), than it is to class a customer as bad when they are good (cost=1). Define the loss function as


Table 7: Cost matrix.
pre(i) and real(i) is the classification results of the ith sample and the actual category, respectively, and f (x) is a piecewise function:

Each sample input the results of logistic regression model as a probability value, if the probability value is greater than a given probability value is the sample classification is 1, otherwise the classification of 0, due to the loss of the two types of error, according to the different probability of loss matrix can be calculated at a given value under the condition of overall losses, the results as shown. It can be seen that when the given probability value is 0.21, the overall loss is the smallest. The Confusion matrix are shown in the Table 8. The precision of the model is 85%. The autocorrelation function diagram and kernel density diagram of all parameters. Monte Carlo simulation starts from the initial value given for each parameter. Due to the randomness of extraction, the first part of extracted value is used as an independent sample obtained by annealing algorithm. Therefore, we must judge the convergence of the extracted Markov Chain. The convergence of Markov chains can be analyzed according to the results of parameter extraction [7].

Table 8: Confusion matrix.
Iteration History Diagram
From the graphs in (Figures 5&6) we can safely conclude that the chains have converged as the plots exhibits no extended increasing or decreasing trends, rather it looks like a horizontal band.

Figure 5: Loss diagram.

Figure 6: Iteration history of Open BUGS.
Nuclear Density Figure
According to the distribution density of extracted samples, it can be seen that the samples extracted by Gibb’s algorithm are mostly concentrated in a small area, which can also explain the convergence of Markov chain [8].
Autocorrelation Diagram
Autocorrelation plots clearly indicate that the chains are not at all autocorrelated. The later part is better since samples from the posterior distribution contained more information about the parameters than the succeeding draws. Almost negligible correlation is witnessed from the graphs in (Figures 7&8) So the samples may be considered as independent samples from the target distribution, i.e. the posterior distribution [9].
Conclusion
This paper constructs a binomial logistic regression model based on the customer characteristic data of Banks. Content mainly includes two parts, the first is the part of data pretreatment, the original data contains 20 variables, in order to make the model more concise, and improve the accuracy of classification model, reduce the cost of information collection and the time cost of customers, using “Boruta” method of screening of three quantitative indicators, and use the optimal segmentation method will be treated as continuous variable section. Then, three qualitative variables were selected into the model by calculating the IV value of the variable, and the qualitative variables were treated with a unique heat type. Two logIST-IC regression of SPSS software was used to screen out 10 variables with significance less than 0.05 into the model.

Figure 7: The Autocorrelation diagram of Open BUGS.

Figure 8: The Nuclear density of Open BUGS.
All the selected variables were brought into Open BUGS software to obtain the parameter Bayesian estimation of the binomial logistic regression model. From the estimation results, it can be seen that the customer’s historical credit (Credit_history) and current economic status (Checking_account_status) have the greatest impact on credit delinquency. Banks should pay more attention to these two aspects when evaluating the customer’s credit risk level [10].
Conflict of Interest
We have no conflict of interests to disclose, and the manuscript has been read and approved by all named authors.
Acknowledgement
This work was supported by the Philosophical and Social Sciences Research Project of Hubei Education Department (19Y049), and the Staring Research Foundation for the Ph.D. of Hubei University of Technology (BSQD 2019054), Hubei Province, China.
References
- Carroll R, Lawson A, Faes C, Kirby R, Aregay M, et al. (2015) Comparing INLA and OpenBUGS for hierarchical Poisson modeling in disease mapping. Spatial and Spation-temporal Epidemiology 14(15): 45-54.
- Lyle W Konigsberg, Susan R Frankenberg (2013) Bayes in biological antropology. American Journal of Physical Anthropology S57:152-163.
- Gamerman D, Lopes H (2006) Markov chain Monte Carlo: Stochastic simulation for Bayesian inference (2nd edn) [M]. New York: CRC Press 2006.
- Rue H, Martino S, Chopin N (2009) Approximate Bayesian inference for latent Gassian models using integrated nested Laplace approximations (with discussion). J R Stat Soc Series B 71(2): 319-392.
- Chen M, Shao Q, lbrahim JR (2000) Monte Carlo methods in Bayesian computation. New York: Springer-Verlag, 2000.
- Lunn DJ, Andrew A, Best N, Spiegelhalter D (2000) WinBUGS-a Bayes modeling framework: concepts, structure extensibility. Stat Comput 10: 325-337.
- Kingma DP, Ba J (2015) Adam A Method for Stochastic Optimization. 3rd International Conference for Learning Representations. San Diego, 2015.
- Srivastava AK, Kumar V (2011) Software reliability data analysis with Marshall-Olkin extended Weibull model using MCMC method for non- informative set of priors. Int J Comput Appl 18(4): 31-39.
- Srivastava AK, Kumar V (2019) Markov Chain Monte Carlo methods for Bayesian inference of the Chen model. Int J Comput Inf Syst 2(2): 7-14.
- Hang Li (2012) Statistical Learning Methods (in Chinese). Beijing: Tsinghua University Press, 2012.
