 Research Article
Research ArticleAbstract
Background: The US healthcare system and the Medicare program have been implementing a range of strategies to encourage the development and use of generic drugs. The current evidence is limited to indicate the patterns of generic drugs use and its predictors among Medicare beneficiaries. Similarly, although relevant the potential of artificial intelligence (i.e. machine learning) in health research has not been significantly explored globally and in the USA.
Objectives: Using the Medicare Current Beneficiary Survey (MCBS) data, this study predicted the determinants of generic drug use among Medicare beneficiaries, using artificial intelligence (i.e. machine learning).
Methods: MCBS data from 2015 and 2016 were included with 26,163 beneficiaries. Multivariable logistic regression was applied to examine associations between generic drug use and key predictors. Random forest machine learning algorithm was used to test the accuracy and strength of predictors.
Results: The prevalence of generic drug use was 38 percent for the pooled sample (38.3% in 2015 and 37.7% in 2016). In the pooled cohort, significant predictors were age below 65 years, non-Hispanic white, education above high school, married, lower annual income (<$25,000), without dual Medicare and Medicaid coverage, without private insurance, having part D coverage, more than two limitations in activities of daily living, and more than 20 outpatient office visits (all: P< 0.05). In the predictive analysis using artificial intelligence (i.e. machine learning algorithm), number of outpatient visits, marital status, race, education, and age were the most important predictors.
Conclusions: Socio- demographic variables along with insurance characteristics were significantly associated with generic drug use under the Medicare program. Policy strategies to encourage generic drug use among higher income groups, non-Hispanic Blacks and less educated beneficiaries may be relevant. Further policy attention required to encourage generic drug use among Medicare beneficiaries with private insurance and part D drug coverage. Machine learning is relevant to explore predictors of generic drug use and other parameters in healthcare.
Keywords: Artificial Intelligence; Machine Learning; Generic Drug Use; US Healthcare System; Medicare; CMS Data
Introduction
The U.S. healthcare system has been considering a variety of strategies to encourage the development and use of generic drugs over brand-name drugs, specifically under the Medicare program [1]. According to the Federal Drug Administration (FDA), generic drugs are copies of brand-name drugs and have the same performance characteristics and quality as their branded counterparts [2]. Generic drugs’ financial savings to the healthcare system is noticeable [1]. FDA reports that generic medications can cost, on average 80 to 85 percent less to patients than the brandname equivalents [2]. Even though generics share 89 percent of drugs dispensed, it only costs 26 percent of total drug costs in the U.S [1]. In 2016 alone, generics saved $253 billion, while generics under Medicare saved $77 billion ($1,883 per enrollee) [1]. With such savings, it can be better invested in medical research and developing new treatments [1]. A recent study indicated that the use of generic medications was associated with comparable clinical outcomes to the use of branded counterparts, specifically for chronic conditions [3]. Under the Medicare Act, the policy approach is to encourage generic drug use. However, it does also cover branded drugs [4]. The Medicare Part D program entitles beneficiaries with branded drug coverage through a stand-alone Medicare Part D Prescription Drug Plan (PDP) or a Medicare Advantage Prescription Drug plan [4]. If a brand-name medication is medically necessary, the out-of-pocket to the patients can be higher depending on their drug plan’s payment structure [4]. Medicare prescription drug plans place drugs into different payment “tiers” with varied costs for each tier [4]. Higher tiers typically have higher co-payments and/or coinsurance costs[4]. In addition, every Medicare Prescription Drug Plan categorizes its covered drugs independently [4].
Promoting generic substitution is known to fetch substantial savings in the Medicare drug benefit program [5]. According to the U.S. Department of Health and Human Services (HHS), the use of generic drugs could have saved $3 billion for the Medicare Part D program in 2016 [6]. Furthermore, if the substitution of generic drugs works program-wide, the Part D could potentially save $5.9 billion a year [6]. CMS reported that although 90% of prescriptions dispensed in the U.S. are for generic drugs, Medicare Part D beneficiaries spent $1.1 billion in 2016 alone on out-of-pocket for branded drugs with generic equivalents [7]. While there are indications that the chance to fill a generic drug is more under the Medicare plans, not much is known about the prevalence of generic drug use and its predictors among Medicare beneficiaries. Knowing the predictors of generic drug use would have policy implications, especially when the Medicare program changes from time to time [8]. The scope of artificial intelligence (AI) has been widely recognized in the US healthcare system and under Medicare [9]. AI integrates the scientific principles of philosophy, mathematics and computer science to understand and develop systems that display and emulate properties of human intelligence [10]. AI is a branch of computer science which enables creation of machines that work and react like human intelligence with training, supervision or automation mode [11]. These machines can complement or replace human intelligence and skills in a healthcare setting. However, AI has been widely discussed as a supporting tool to replace human skills to enhance availability and quality of healthcare through disruptive technology [12]. The potential of AI has not been widely explored for data exploration and research [13].
When it comes to health research, machine learning is the most recognized AI tool. Machine learning uses algorithms and a wide range of statistical models to learn associations of predictive power from examples in data [10]. It has an incredible pattern recognizing ability in big and raw data sets. This identification of patterns helps in knowing healthcare seeking patterns and quality and their determinants in complex healthcare systems. Machine learning thus helps quick decision making without much costs and time. It should be noted that although machine learning is one of the most tangible manifestation of AI with a wider scope in healthcare research, it is still an emerging concept in health research globally and in the USA [14].
Objectives
The objectives of the study were two-fold. First, using the Medicare Current Beneficiary Survey (MCBS) data, it quantified the national prevalence of generic drug use among Medicare beneficiaries. Secondly, it identified the predictors of generic drug use among such populations through the application of artificial intelligence (i.e. machine learning). In short, this study tried to generate novel evidence on generic drug use among Medicare beneficiaries and also tried to apply machine learning in complex Medicare data for predictive modelling.
Materials and Methods
Data Source
The data were obtained from the 2015 and 2016 Medicare Current Beneficiary Survey (MCBS) conducted by the Center for Medicare and Medicaid Services (CMS), which includes nationally representative sample of the Medicare population [15]. The survey collects information from community dwelling Medicare beneficiaries on self-reported socio-demographics, health status, health behaviors, as well as health insurance, utilization, and access to care. In 2015, there were 12,311 Medicare beneficiaries in the survey sample representing a weighted sample of 52.4 million beneficiaries, whereas there were 12,852 survey beneficiaries in 2016 representing a weighted sample of 53.5 million. Thus, our total sample was 25,163 beneficiaries across both survey years.
Outcome Variable
A binary dependent variable - use of generic drug - was created for the analysis. In the MCBS data, an item “ever asked for generic drug” was collected with three possible responses - “never”, “sometimes” and “often”. We recoded the responses “sometimes” and “often” to “ever”, creating a dichotomous variable for generic drug use to either “ever” or “never”.Predictors
Demographic, socio-economic, insurance, health status and healthcare utilization variables were used as predictors. Demographic predictors included gender, race, age, and marital status. Gender was a binary variable consisting of males and females. Race included four categories – “non-Hispanic whites”, “non-Hispanic blacks”, “Hispanics” and “others”. There were three age groups – below 65 years, 65 to 75 years, and above 75 years. Marital status consisted of four categories – “married”, “widowed”, “divorced/ separated”, and “never married”. Socio-economic predictors were education, annual income, and place of stay. There were three education categories – “less than high school”, “high school or vocational, technical, business, etc.”, and “more than high school”. Annual income was dichotomized creating income below and above $25,000. Place of stay was also a binary variable of respondents from metro and non-metro regions. Insurance predictors consisted of dual coverage (Medicare and Medicaid), whether plan covered drugs, Part D coverage, and enrollment in Medicare Advantage and private insurance. All insurance predictors were binary variables with “yes” or “no” responses. Number of limitations in activities of daily living (ADLs) was the health status predictor. ADLs are limitations to caring for the self as a result of a health or physical issue. Caring for the self includes activities such as bathing, showering, dressing up, eating, getting in or out of bed or chairs, or using toilets. ADL predictor was coded as three responses – none, one, and two or more. Healthcare utilization predictors were number of outpatient office visits, and number of inpatient stays. Both outpatient office visit and inpatient stay variables were categorized into six responses – “no office visit”, “1 to 5 office visits”, “6 to 10 office visits”, “11 to 15 office visits”, “16 to 20 office visits”, and “21 or more office visits”.Statistical Methods
Descriptive analyses conducted for the predictors and the sample characteristics were presented by sub-groups under each predictor as weighted proportions. Correlation was tested among all predictors with the Pearson’s correlation coefficient. Enrollment in the Medicare Advantage Plan was highly correlated with outpatient visits (correlation coefficient -0.66) and private insurance (correlation coefficient -0.83). Thus, enrollment in the Medicare Advantage Plan was dropped from the list of predictors. Bivariable analyses were performed using Rao-Scott tests to demonstrate possible associations between the dependent variable and predictors [16]. Separate Rao-Scott tests were conducted by year cohort (2015 and 2016) and for the pooled cohort. Associations between generic drug use and predictors (demographic, socioeconomic, insurance, and healthcare utilization) were estimated using a multivariable logistic regression model. Associations were considered statistically significant if the p-value was below 0.05. All estimates were weighted by using sample weights to represent the population of all ‘‘ever-enrolled’’ Medicare beneficiaries. Artificial intelligence through a machine learning algorithm was used to improve the predictive modelling for the predictors of generic drug use [9]. We used an ensemble model (random forest) to predict the outcome. Random forest is a supervised machine learning algorithm which uses a combination of decision trees [17]. Decision trees consist of recursively partitioning the inputs (predictors).
The algorithm sequentially fits new attributes to predict the output. In our model, an ensemble of 501 decision trees was used and trees were extended up to a maximum depth of 10. First, the random forest model was trained on 80% of the observations and was validated on the remaining 20% of observations for predictive strength. A ten-fold cross-validation of the data was performed where the data was split into 80% training and 20% test observations randomly ten times, and the average of these ten splits was taken as the final prediction estimate. We tested three random forest models on the pooled cohort sample based on different variable selection. In the first model, generic drug use was predicted against socio-demographic variables. The second model utilized health utilization and insurance predictors, while the third model utilized all socio-demographic, health utilization, and insurance predictors. The models were evaluated with accuracy, sensitivity (ratio of correctly predicted positive observations to all actual positives) and specificity of prediction (ratio of correctly predicted negative observations to the total of all actual negatives) along with receiver operating characteristics (ROC) curve and area under ROC curve (AUC). Finally, relative contributions of the predictors were estimated with relative decrease in Gini index. All statistical analyses were performed with Stata 15 software and R programming language [18,19].
Result
Participants
As shown in the Table 1, there were 12,311 and 12,852 respondents in 2015 and 2016 cohorts respectively with a combined population of 25,163 respondents. The gender distribution was similar across the cohorts with females representing 54 percent of the sample (54.8% in 2015, 54.2% in 2016 and 54.5% in pooled sample). Around half of the sample belonged to the age group of 65 to 75 years, while about two-thirds were above 75 years. A vast majority of respondents were non-Hispanic whites (73.9% in 2015, 74.7% in 2016 and 74.3% in pooled cohort). Relatively higher number of respondents had an annual income of more than $25,000 (59.5% in 2015, 61% in 2016 and 60.3% pooled cohort). Most of the respondents belonged to metro regions. Slightly lower than 50% respondents reported having above high school level education (47.4% in 2015, 49.8% in 2016 and 48.6% in pooled cohort), while around one-third reported high school education. More than a half were married and had no limitations in activities of daily living. In terms of insurance coverage, more than 80% did not have dual Medicare and Medicaid coverage and close to threefourths had Part D coverage. While more than half (54.8% in 2015, 54.2% in 2016 and 54.5% in pooled cohort) had private insurance, about a third were enrolled in the Medicare Advantage plans. About two-thirds had drugs covered under their plans (65.5% in 2015, 66.6% in 2016 and 66.1% in pooled cohort). Descriptive data Table 2 presents results from the bivariable analyses where the outcome (asking for generic drugs) was compared by various socio-demographic and health utilization variables. Overall, 38.3% of respondents in 2015 cohort and 37.7% in 2016 cohort reported the use of generic drugs. More males asked for generic drugs than females in the 2015 cohort, whereas the gender distribution was reversed in the 2016 cohort in favor of females. Significantly higher proportions of respondents from the 65 to 75 years age group asked for generic drugs across the cohorts (P<0.001).
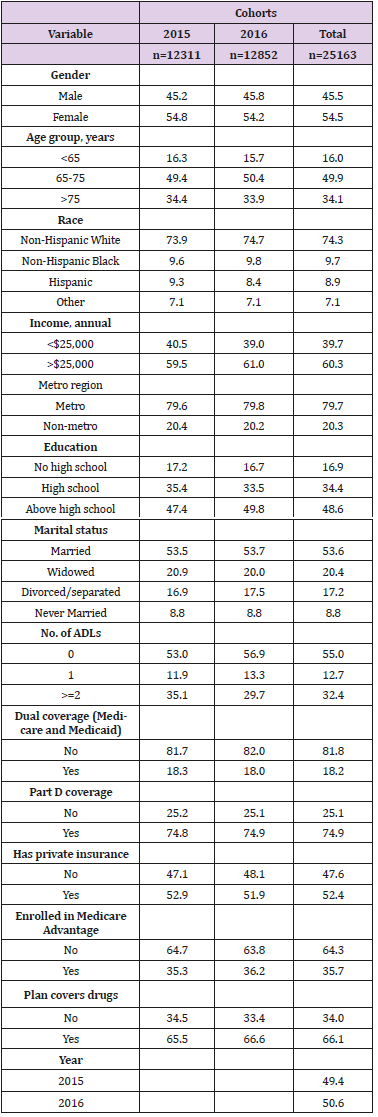
Table 1: Socio-demographic characteristics of the sample.
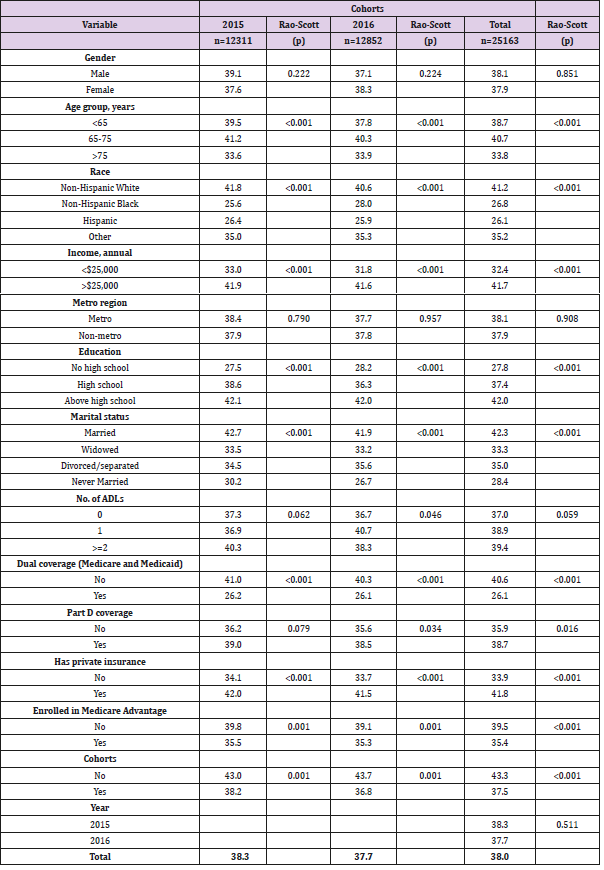
Table 2: Prevalence of generic drug use among Medicare beneficiaries.
Non-Hispanic whites, respondents with higher income and above high school level education were more likely to use generic drugs (P<0.001). All insurance related predictors were significantly associated with generic drug use. A higher proportion of respondents without dual coverage, who were not enrolled in the Medicare Advantage plans and had no plans for covering drugs were likely to use generic drugs. On the other hand, more respondents with Part D coverage and private insurance were likely to ask for generic drugs. Except for Part D coverage, the bivariable results were similar in both 2015 and 2016 cohorts. Table 3 shows the socio- demographic, health, and insurance utilization factors associated with generic drug use among Medicare beneficiaries through multivariable logistic analysis. In the 2015 cohort, below 65 years, male, non-Hispanic whites, education above high school, married, having lower annual income (<$25,000), without dual coverage, without private insurance, with Part D coverage, having more than two limitations in activities of daily living, and more than 20 outpatient office visits were significantly (all: P< 0.05) associated with higher odds of generic drugs use. Similar associations were also observed in the 2016 cohort except for gender and income predictors, which were not significantly associated. The pooled cohort had similar associations to the 2015 cohort excluding gender. In the predictive analysis using machine learning, the model with only socio-demographic explanatory variables had high sensitivity (99.5%), but low specificity (0.4%) and an accuracy of 62.2% (95% CI 60.6%-63.7%) for prediction. The area under receiver operating characteristics curve (AUC) was 52.9%. With the insurance variables, the sensitivity came down to 95.9% and specificity went up to 8%, while the accuracy increased marginally to 62.7% (95% CI 61.2%-64.2%); however, the AUC was the least at 44.7%. Finally, the combined model (socio-demographic and insurance variables) achieved the best balance between the sensitivity (92.3%) and specificity (13.7%) values. This model also outperformed other two models in terms of accuracy (62.8%) and AUC (58.2%). Figure 1 presents the ROC and AUC for these three models. In the combined model, number of outpatient visits, marital status, race, education and age were the most important predictors for generic drug use (Figure 2).
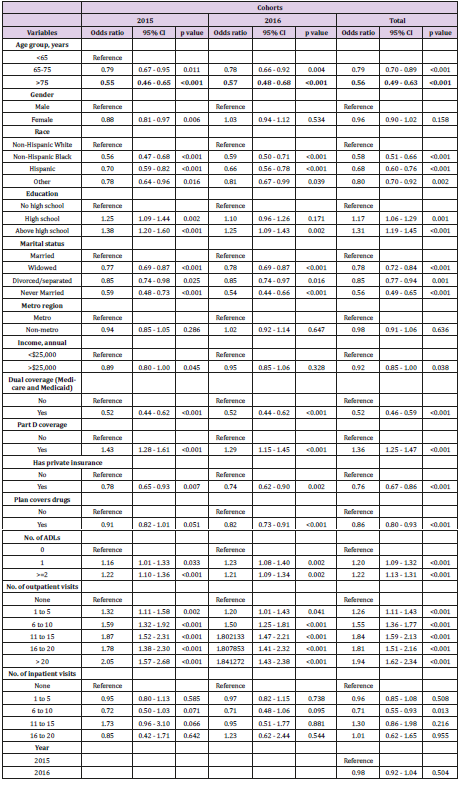
Table 3: Association between generic drug use and socio-demographic determinants.
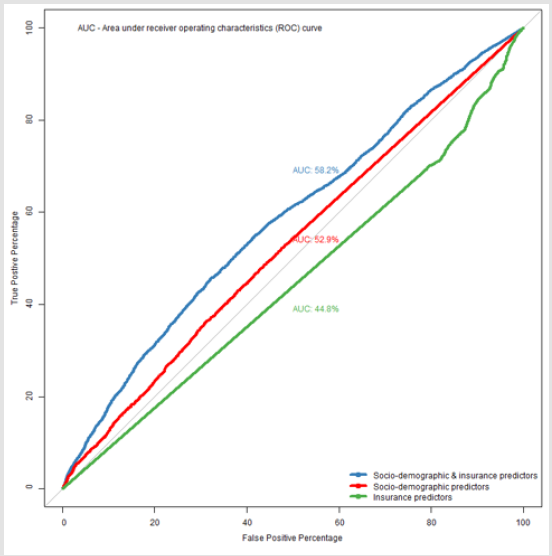
Figure 1: Performance of random forest models with different predictors.
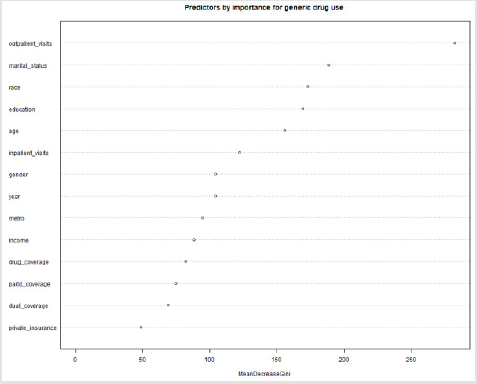
Figure 2: Relative contribution of different predictors in the random forest model.
Discussion
Our study showed that the odds of generic drug use was relatively higher among Medicare beneficiaries who were below 65 years, non-Hispanic whites, education above high school, married, without dual coverage, without private insurance, with Part D coverage, having more than two limitations in activities of daily living, and more than 20 outpatient office visits. In the 2015 cohort alone, being a male and having lower annual income (<$25,000) were also associated with a higher chance of generic drug use unlike in the 2016 cohort. The pooled cohort had similar associations to the 2015 cohort excluding gender predictor. In the predictive analysis using machine learning, number of outpatient visits, marital status, race, education and age were the most important predictors for generic drug use in the pooled cohort. A recent study also showed dispensing of generic drugs is consistently high (74%) among Medicare beneficiaries compared to the commercial beneficiary population in the last few years. [20] Also, existing evidence reflected a higher proportion of generic drugs use, especially for chronic conditions among white populations [20]. There are also indications of increased healthcare utilization, especially for annual wellness visits among non-Hispanic whites [15]. In contrast to our findings, a recent study found high generic drug use among older adults, specifically for chronic health conditions (e.g., thyroid disorders) [20]. Our study showed this probability to be higher among adults under 65 years. We did not observe this trend as we did not examine the drug dispensing patterns for various health conditions. It is true that the nature of disease and health condition could be a driver of dispensing drugs [21]. More generic drug use among adults below 65 years compared to above 65 groups perhaps could be due to medical necessity for prescription drugs [20]. Similar to our findings in the 2015 cohort, another study also found that the use of branded drugs was relatively less among males [21]. This gender difference in dispensing generic drugs was not observed in the 2016 cohort, indicating that perhaps the awareness and need for cost-effective generic drugs have spread eventually to both genders under the Medicare program [1]. Prevailing evidence confirms our findings that beneficiaries with the Part D coverage are more likely to avail generic drugs [22]. One of the reasons could be prescription formulary benefit design targeting increased the use of low-cost generic drugs under the Part D coverage [23]. Additional policy measures such as not increasing generic drug price and wider availability of generic drugs, including fast tracking generic drug applications will further ensure this reliance on generic drugs under other components of the Medicare program. Typically, if healthcare utilization involves a higher out-of-pocket expenditure on branded drugs, only higher income groups will be more inclined to avail care and branded drugs [15].
Our study also found that generic drugs use was higher among lower income groups. Lower affordability could be a reason for a direct association between number of outpatient visits and generic drug use in the study. Lower income groups have better affordability for generic drugs and generic drugs have better patient compliance, especially among low income groups [1]. Around 20 percent of brand-name prescriptions are abandoned, compared to 7.7 percent of generics among approved claims in 2016 under the Medicare program [1]. Since generic drugs are more cost saving, policy strategies are needed to encourage generic drugs use even among higher income groups under the Medicare program. Although health conditions can be predictors of generic drug use, this study did not consider health conditions [24]. CMS asks respondents “did you ever diagnose with a specific health condition?” The responses would not have necessarily matched with the study period under consideration. However, this study included number of limitations in activities of daily living (ADLs), number of outpatient office visits and number of inpatient stays. Nonetheless, health conditions could be potential confounders, driving the effect sizes in this study. Also, this study was only among Medicare beneficiaries and findings are not generalizable beyond this population.
Conclusion
This study finds that socio-economic and demographic variables along with insurance characteristics play a significant role in the chance and level of generic drug use under the Medicare program. Policy strategies to encourage generic drug use among higher income groups, non-Hispanic Blacks, less educated beneficiaries, private insurance holders and part D Medicare coverage may be relevant. Machine learning could be applied further to understand predictors of generic drug use and other health parameters in complex big and raw data in the USA and elsewhere.
Author contributions
AKD, HB and SSG conceptualized the study design, analyzed data and drafted the manuscript. All authors finally agreed to the final version.
Conflict of Interest
None declared by the authors. Views expressed in the paper are that of the authors and do not necessarily reflect that of their organizations.
References
- (2017) AAM, Generic drug use and access in the US. Washington DC, USA.
- (2017) US Food and Drug Administration (FDA), The Generic Drug Approval Process. Washington DC.
- K Desai RJ, Sarpatwari A, Dejene S, NF, Lii J, Rogers JR (2019) Comparative effectiveness of generic and brand-name medication use: A database study of US health insurance claims. PLoS Med 16(3): e1002763.
- (2017) Medicare What Medicare Covers. Washington DC, USA.
- Sacks CA, Lee CC, Kesselheim AS (2018) Medicare Spending on Brand-name Combination Medications vs Their Generic Constituents. JAMA 320(7): 650-656.
- (2018) Healthpayer intelligence Public payer news. Healthpayer intelligence.
- (2018) Med city news Medicare Part D plans should step up on generic drug utilization, CMS administrator says.
- Powell HB (2018) Medicare Part D payments for brand and generic drugs prescribed by dermatologists. J Am Acad Dermatol 79(3): 575-577.
- ZH Wei Hsuan, Lo Ciganic, Huang JL (2019) Evaluation of Machine-Learning Algorithms for Predicting Opioid Overdose Risk Among Medicare Beneficiaries with Opioid Prescriptions. JAMA Netw Open 2(3): e190968.
- T Panch, P Szolovits, R Atun (2018) Artificial intelligence, machine learning and health systems. J Glob Health 8(2): 020303.
- P Tamilselvan, P Wang (2013) Failure diagnosis using deep belief learning based health state classification. Reliab Eng Syst Saf 115: 124-135.
- SA Bini (2018) Artificial Intelligence, Machine Learning, Deep Learning, and Cognitive Computing: What Do These Terms Mean and How Will They Impact Health Care? J Arthroplasty 33(8): 2358-2361.
- F Jiang (2017) Artificial intelligence in healthcare: Past, present and future. Stroke and Vascular Neurology 2(4).
- DJ Morgan (2019) Assessment of Machine Learning vs Standard Prediction Rules for Predicting Hospital Readmissions. JAMA Netw. Open 2(3): e190348.
- PM Lind KE, Hildreth K, Lindrooth R, Crane LA (2018) Ethnoracial Disparities in Medicare Annual Wellness Visit Utilization Evidence from a Nationally Representative Database. Med Care 56(9): 761-766.
- JNK Rao, AJ Scott (1984) On Chi-Squared Tests for Multiway Contingency Tables with Cell Proportions Estimated from Survey Data. Ann Stat 12(1): 46-60.
- Viktor CV, Fadia ST (2017) Tree-based Claims Algorithm for Measuring Pretreatment Quality of Care in Medicare Disabled Hepatitis C Patients. Med Care 55(12): e104-e112.
- StataCorp (2017) Stata Statistical Software. Release 15. StataCorp LLC,College Station, TX, College Station, TX.
- (2017) R Core Team A language and environment for statistical computing. R Foundation for Statistical Computing, Vienna, Austria, Vienna, Austria.
- Ross JS, Rohde S, Sangaralingham L, Brito JP, Choi L (2019) Generic and Brand-Name Thyroid Hormone Drug Use among Commercially Insured and Medicare Beneficiaries, 2007-2016. J Clin Endocrinol Metab 104(6): 2305-2314.
- BT Shrank WH, Choudhry NK, Liberman JN (2011) The use of generic drugs in prevention of chronic disease is far more cost-effective than thought and may save money. Heal Aff 30(7): 1351-1357.
- ZJ Joyce G, Henkhaus LE, Gascue L (2018) Generic Drug Price Hikes and Out-Of-Pocket Spending for Medicare Beneficiaries. Heal Aff 37(10): 1578-1586.
- QJ Hohmann N, Hansen R, Garza KB, Harris I, Kiptanui Z (2018) Association between Higher Generic Drug Use and Medicare Part D Star Ratings: An Observational Analysis. Value Heal 21(10): 1186-1191.
- BD Hartung DM, Johnston KA, Irwin A (2019) Trends in Coverage for Disease-Modifying Therapies for Multiple Sclerosis in Medicare Part D. Heal Aff 38(2): 303-312.
